-
[인프런 - 파이썬 머신러닝 완벽 가이드] 데이터 전처리 (데이터 인코딩과 스케일링)Data Science 2020. 6. 8. 00:35반응형
데이터 전처리 (Preprocessing)
- 데이터 클린징
- 결손값 처리(Null/NaN 처리)
- 데이터 인코딩 (레이블, 원-핫 인코딩)
- 데이터 스케일링
- 이상치 제거
- feature 선택 추출 및 가공
1. 데이터 인코딩
머신러닝 알고리즘에 사용되는 데이터는 모두 숫자형으로 표현되어야 한다.
즉 카테고리컬한 값이나 문자형 값은 모두 숫자값으로 변환,인코딩 되어야한다.
레이블 인코딩 (label encoding)
from sklearn.preprocessing import LabelEncoder items = ["TV", "냉장고", "전자렌지", "컴퓨터", "선풍기", "선풍기", "믹서", "믹서"] #Label Encoder를 객체로 생성한후 fit()과 transform() 으로 label 인코딩 수행 encoder = LabelEncoder() encoder.fit(items) labels = encoder.transform(items) print('인코딩 변화값: ',labels) print('인코딩 클래스: ',encoder.classes_) print('디코딩 원본 값: ',encoder.inverse_transform([4,5,2,0,1,1,3,3]))
원 - 핫 인코딩 (One-Hot encoding)
feature 값의 유형에 따라 새로운 feature를 추가하고 고유값에 해당하는 컬럼의 값을 1로 표시하고 나머지 컬럼에는 0을 표시
from sklearn.preprocessing import OneHotEncoder import numpy as np items = ["TV", "냉장고", "전자렌지", "컴퓨터", "선풍기", "선풍기", "믹서", "믹서"] # 먼저 숫자값으로 변황을 위해 Label Encoder로 변환 encoder = LabelEncoder() encoder.fit(items) labels = encoder.transform(items) print(labels) # 2차원 데이터로 변환 labels = labels.reshape(-1,1) print(labels) # 원 - 핫 인코딩 적용합니다. oh_encoder = OneHotEncoder() oh_encoder.fit(labels) oh_labels = oh_encoder.transform(labels) print("원-핫 인코딩 데이터") print(oh_labels.toarray()) print("원-핫 인코딩 데이터 차원") print(oh_labels.shape)
get_dummies() 를 사용해 위 코드를 간략하게 할수있다.
import pandas as pd df = pd.DataFrame({'item':['TV', '냉장고', '전자렌지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']}) print(df) print(pd.get_dummies(df))
2. 스케일링
StandardScaler : 평균이 0이고 분산이 1인 정규 분포 형태로 변환
from sklearn.preprocessing import StandardScaler # StandardScaler # 평균이 0이고 분산이 1인 정규분포 형태로 변환 scaler = StandardScaler() # StandardScaler로 데이터셋 변환 fit() 과 transform() 호출 scaler.fit(iris_df) iris_scaled = scaler.transform(iris_df) # transform()시 scale 변환된 데이터셋이 numpy ndarray로 반환되어 이를 DataFrame으로 변환 iris_df_scaled = pd.DataFrame(data=iris_scaled , columns=iris.feature_names) print(iris_df_scaled) print('feature 들의 평균값') print(iris_df_scaled.mean()) print('feature 들의 평균값') print(iris_df_scaled.var())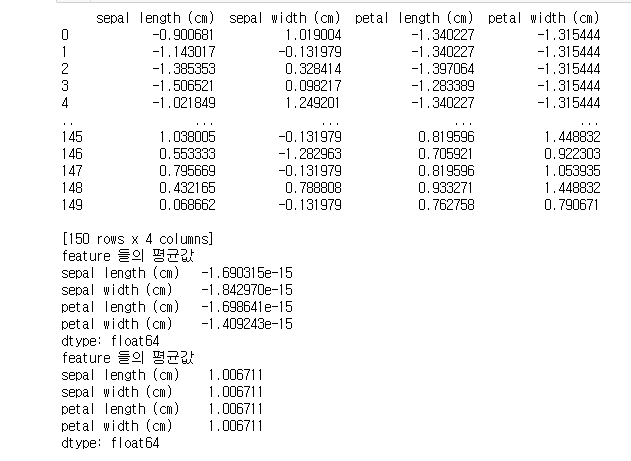
MinMaxScaler
from sklearn.preprocessing import MinMaxScaler # MinMaxScaler 객체 생성 # 데이터값을 0과 1사이 범위값으로 변환 (음수값이 있으면 -1에서 1값으로 변환) scaler = MinMaxScaler() # MinMaxScaler로 데이터셋 변환 fit() transform() 호출 scaler.fit(iris_df) iris_scaled = scaler.transform(iris_df) # transform()시 scale 변환된 데이터셋이 numpy ndarray로 반환되어 이를 DataFrame으로 변환 iris_df_scaled = pd.DataFrame(data=iris_scaled , columns=iris.feature_names) print(iris_df_scaled) print('feature 들의 최소 값') print(iris_df_scaled.min()) print('feature 들의 최대 값') print(iris_df_scaled.max()) 반응형
반응형'Data Science' 카테고리의 다른 글
[인프런 - 파이썬 머신러닝 완벽 가이드]머신러닝 classification(분류) 성능 지표 - 정밀도(Precision)과 재현율(Recall) (0) 2020.06.09 [인프런 - 파이썬 머신러닝 완벽 가이드] 머신러닝 classification(분류) 성능 지표 - 정확도 Accuracy , 오차 행렬 (Confusion Matrix) (0) 2020.06.09 [인프런 - 파이썬 머신러닝 완벽 가이드] 교차 검증 (0) 2020.06.08 [인프런 - 파이썬 머신러닝 완벽 가이드] iris 품종 예측하기 (0) 2020.06.07 [Data Science] 공공데이터 활용해 프랜차이즈 분석하기 (0) 2020.06.06